Single Linked List
merupakan suatu sistem penyimpanan dimana memori yang digunakan untuk penyimpanan digunakan secara dinamis (memori yang digunakan sesuai dengan ukuran dari data yang ditampung)
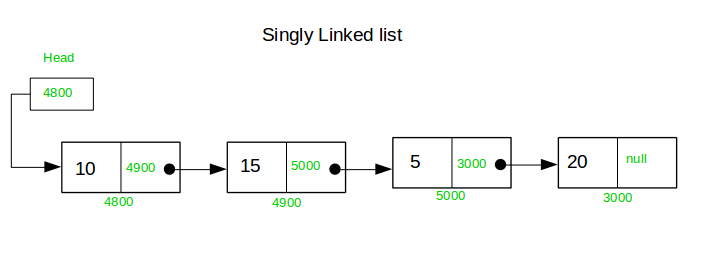
Struktur Single Linked List (node) :
- Data yang ditmapung, dapat berupa : char,int, bool dan sebagainya
- Pointer next yang merefernce ke alamat node setelahnya
Pendeklarasian:
Pendeklarasian:
struct Mahasiswa{
char nama[20];
char nim[20];
struct Mahasiswa * next;
};
Dalam Single Linked List dapat dilakukan juga :
Insert, Delete maupun Update
Ada beberapa cara dalam menginsert node baru :
- Insert di awal (head)
- Insert di awal (head)
- Insert di akhir (tail)
- Insert di next dari node yang ditunjuk
Double Linked List
merupakana salah satu perkembangan dari single linked list yaitu penyimpanan data secara dinamis (menggunakan memori secukupnya)

Struktur Double Linked List :
- Data yang ditampung, dapat berupa int , char , bool dan sebaginaya
- Pointer next yang mereference ke node selanjutnya
- Pointer prev yang mereference ke node sebelumnya
Perbedaan antara Double Linked List & Single Linked List :
- Double Linked List lebih boros memori tetapi memilki kceepatan pencarian lebih cepat jika dibandingkan dengan Single Linked List karena memilki tambahan pointer yaitu pointer prev
- Double Linked List mempermudah jika ingin melakukan pencaraian data secara descending
Pendeklarasian:
struct Mahasiswa{
char nama[20];
char nim[20];
struct Mahasiswa * next;
struct Mahasiswa * prev;
};
Dalam Doubly Linked List dapat dilakukan juga :
Insert, Delete maupun Update
Ada beberapa cara dalam menginsert node baru :
- Insert di awal (head)
- Insert di awal (head)
- Insert di akhir (tail)
- Insert di next dari node yang ditunjuk
- Insert di prev dari node yang ditunjuk
Circular Single Linked List
Perbedaan antara ciruclar single linked list dan single linked list biasa terdapat di bagian tail.
Di bagian tail dari circular single linked list pointer "next" nya tidak akan menunjuk ke null melainkan akan menunjuk ke awal node (head) sehingga tidak terdapat node yang isinya null
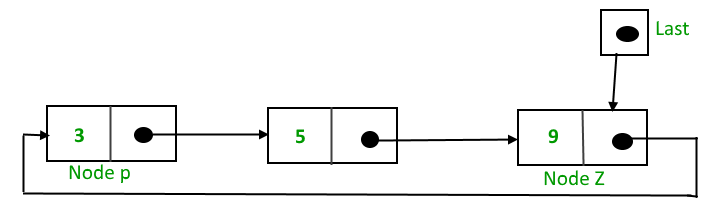
Circular Double Linked List
Perbedaan hampir sama seperti Circular Single Linked List dimana tidak akan ada nilai null di linked list tersebut.
Di Circular Double Linked List, head akan memilki "prev"yang akan menunjuk pada tail dan tail akan memilki "next" yang akan menunjuk ke head
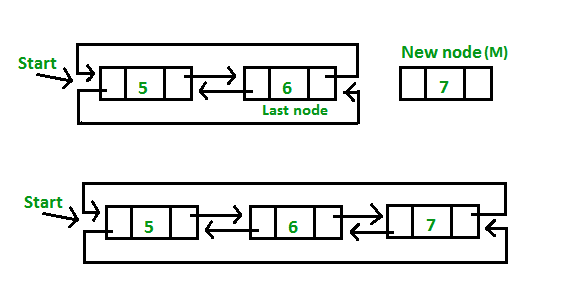
Keuntungan :
- Linked list menjadi reversible
- Untuk pindah dari head ke tail maupun tail ke head lebih cepat dengan konstan waktu O(1)
Kekurangan :
- Membutuhkan memori lebih banyak dalam melakukan "prev"
- Banyak pointer yang dikaitkan sehingga dalam penggunaan pointer harus lebih teliti dan hati - hati
Contoh pengimplementasian :
- Menghandle pembuatan playlist lagu
- Menghandle shopping cart di online shop
Stack & Queue
Stack adalah konsep dimana dalam suatu linked list akan dilakukan penghapusan pada node terakhir baru node sebelumnya atau biasa orang menyebutnya dengan konsep "LIFO" (Last In First Out)
Konsep Stack :
- Pop : untuk menghapus data
- Pop : untuk menghapus data
- Push : untuk menambah data baru
- Insert dan delete dari awal data 'top'
 Queue adalah konsep dimana node pertama yang masuk akan meninggalkan node tersebut duluan atau bisa dibilang sesuai dengan artinya yaitu 'antri'. Jadi Queue menggunakan konsep 'FIFO' (First In First Out)
Queue adalah konsep dimana node pertama yang masuk akan meninggalkan node tersebut duluan atau bisa dibilang sesuai dengan artinya yaitu 'antri'. Jadi Queue menggunakan konsep 'FIFO' (First In First Out)
- Enqueue : menambah data
- Dequeue : menghapus data
- Insert dimulai dari data terakhir
- Delete dimulai dari data pertama

Hash Map
adalah suatu array yang mempunyai sekumpulan data yang ditampung sesuai dengan index arraynya, karena menggunakan index sebagai acuan / patokan sehingga pencarian data menjadi lebih cepat
Collision
Karena hashmap hanya tergantung pada index sehingga dalam pemasukan data dapat mengalami istilah "collision" sehingga ada beberapa cara agar collision dapat dicegah yaitu :
1. Chaining :
Jika data memilki hasil hashing yang sama maka index hashing tersebut akan dibuat menjadi sebuah linked list sehingga collision tidak dapat terjadi
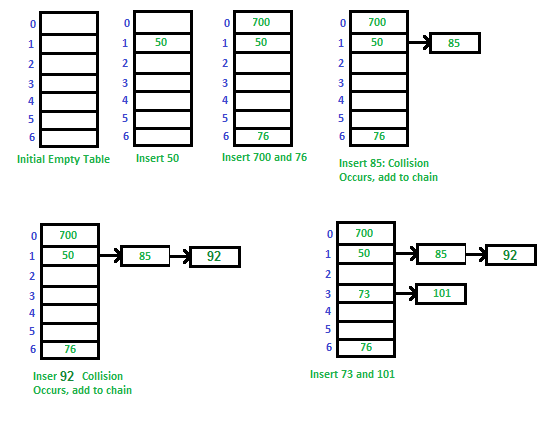
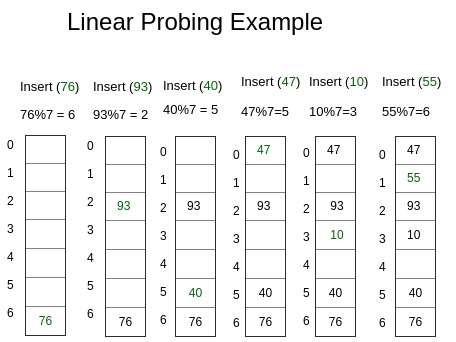
2. Linear probling
adalah salah satu cara ketika memasukkan data ke hash mapnya tidak terjadi collision. Linear probling akan terjadi ketika pemasukkan data ke index tersebut tetapi index tersebut telah terisi dan akan terus mencari index yang kosong baru mengisi data tersebut
Binary Search Tree
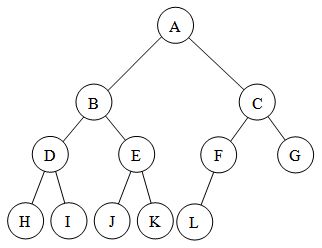
BST merupakan suatu metode menganalisa node yang menggunkan konsep seperti pohon yaitu memiliki ranting. Ranting tersebut dibagi menjadi 2 macam, yaitu ranting sebelah kiri dan kanan, dimana ranting sebelah kiri merupakan kumpulan node yang lebih kecil dari induknya yaitu yang bagian tengah dan terdapat juga ranting yang sebelah kanan dimana akan berisi kumpulan node yang valuenya lebih besar dari node induknya.
Ciri - ciri BST:
- Menggunkan konsep relationship antara parent dan child
- Setiap parent node dapat mempunyai nol anak sampai dengan 2 anak(satu di sebelah kiri dan satu di sebelah kanan)
- Setiap subtree mempunyai subbranches di sebelah kanan maupun di sebelah kirinya
- Setiap node memilki nilai valuenya sendiri
- Node yang terletak di sebelah kiri dari si induk memilki value lebih kecil dari si induk dan lebih besar di sebelah kanan si induk.






Tipe - tipe BST :
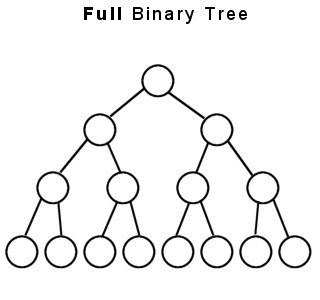
- Full Binary Tree : BST yang dimana setiap node memilki anak (kecuali yang paling akhir -> leaves)
- Complete Binary Tree : BST yang setiap level nya memilki anak kecuali yang terakhir
- Balanced / Perfect Binary Tree : setiap node memilki level yang sama dan terdapat anak dalam setipa node
Metode Insert :
- Misalkan kira ingin memsukkan node yang nialinya 10, kita compare dulu dengan si induk, apabila si induk nialinya lebih besar dari nilai yang kita cari maka kita mulai mencari dari anak yang sebelah kiri dan kemudian kita compare lagi, nilai 7 memilki nilai yang lebih keci dari pada 10 maka kita compare lagi dengan anak yang sebelah kanannya yaitu 9 dan memilki nilai yang lebih kecil lagi maka kita cek dulu apakah si 9 memilki anak atau tidak , jika tidak ada maka kita masukkan 10 menjadi anak dari si 9
Metode Seraching :
Misalkan kita ingin mencari si nilai 10, maka kita comparedulu apakah nilai si induk lebih besar aau lebih besar dari si induk, apabila nilainya lebih besar maka kita compare lagi dengan si anaknya yang sebelah kiri apabila nilai anak yang sebelah kiri lebih kecil atau tidak sama dengan si 10 maka kita compare dengan anaknya yang sebelah kanannya dan di compare terus sampai nilainya ketemu. Apabila nilai yang dicari tidak ketemu maka akan direturn -1.

Metode Delete :
Case 1 : Node yang ingin dihapus tidak memilki anak sama sekali maka langsung dihapus saja si value tesebut.

Case 2 : Node yang ingin dihapus memilki hanya satu anak maka anaknya langsung disambungkan dengan si parent dari node yang dihapus.
Case 3 : Node yang ingin dihapus memilki dua anak (child)
Ada 2 cara :
- In Order Predecessor : menghpus node tersebut dan digantikan dengan nilai terbesar dari node sebelah kiri dari node yang dihapus
- In Order Successor : menghapus node tersebut dan digantikan dengan nilai tersbesar dari node sebelah kanan dari node yang dihapus
Hasil Codingan saya untuk program yang bapak request :
#include <stdio.h>
#include <string.h>
#include <windows.h>
#include <stdlib.h>
#include <time.h>
struct Cart{
char productName[30];
int quantity;
int price;
struct Cart* next;
struct Cart* prev;
}*head = NULL, *tail = NULL;
struct Cart* createNewCart(char productName[], int quantity, int price){
struct Cart* newCart = (struct Cart*)malloc(sizeof(Cart));
strcpy(newCart->productName,productName);
newCart->quantity = quantity;
newCart->price = price;
newCart->next = NULL;
newCart->prev = NULL;
return newCart;
}
void pushHead(char productName[], int quantity, int price){
struct Cart* newCart = createNewCart(productName, quantity, price);
if (!head){
head = tail = newCart;
}
else{
newCart->next = head;
head->prev = newCart;
head = newCart;
}
}
void pushTail(char productName[], int quantity, int price){
struct Cart* newCart = createNewCart(productName, quantity, price);
if (!head){
head = tail = newCart;
}
else{
newCart->prev = tail;
tail->next = newCart;
tail = newCart;
}
}
void pushMid(char productName[], int quantity, int price){
bool valid = true;
if (!head){
struct Cart* newCart = createNewCart(productName, quantity, price);
head = tail = newCart;
}
else{
if (head->price > price){
pushHead(productName, quantity, price);
}
else if (tail->price < price){
pushTail(productName, quantity, price);
}
else{
struct Cart* curr = head;
while(curr){
if(curr->productName == productName){
curr->quantity = quantity;
curr->price = price;
valid = false;
break;
}
if (curr->quantity > quantity){
break;
}
curr = curr->next;
}
if (valid){
struct Cart* newCart = createNewCart(productName, quantity, price);
newCart->prev = curr->prev;
newCart->next = curr;
curr->prev->next = newCart;
curr->prev = newCart;
}
}
}
}
void popHead(){
if (!head){
return;
}
else if (head == tail){
struct Cart* temp = head;
head = tail = NULL;
free(temp);
}
else{
struct Cart* temp = head;
head = head->next;
head->prev = NULL;
free(temp);
}
}
void popTail(){
if (!head){
return;
}
else if (head == tail){
struct Cart* temp = head;
head = tail = NULL;
free(temp);
}
else{
struct Cart* temp = tail;
tail = tail->prev;
tail->next = NULL;
free(temp);
}
}
void popMid(char nama[]){
if (!head){
return;
}
else{
if (strcmp(head->productName,nama)==0){
popHead();
}
else if (strcmp(tail->productName,nama)==0){
popTail();
}
else{
struct Cart* curr = head;
while(curr){
if (strcmp(curr->productName,nama)==0){
break;
}
curr = curr->next;
}
curr->next->prev = curr->prev;
curr->prev->next = curr->next;
free(curr);
}
}
}
int view(int index){
struct Cart* curr = head;
int i = 1;
int total;
if (!head){
printf("Currently there is nothing in cart...\n\n");
printf("Press any key to continue...\n");getchar();
return 0;
}
else{
printf("====================================================\n");
printf("| No | Product's Name | Quantity | Price |\n");
printf("====================================================\n");
while(curr){
printf("| %2d | %20s | %9d | %8d |\n",i,curr->productName,curr->quantity,curr->price);
total += (curr->price*curr->quantity);
i++;
curr = curr->next;
}
printf("====================================================\n\n");
printf("Press any key to continue...\n");getchar();
if (index == 0){
return i-1;
}
else if (index == 1){
return total;
}
}
}
void buy(){
char productName[20];
do{
printf("Input product's name [2 - 20 characters] : ");scanf("%s",productName);
}while(strlen(productName) < 2 || strlen(productName) > 20);
int quantity = 0;
do{
printf("Input quantity [1 - 50] : ");scanf("%d",&quantity);getchar();
}while(quantity < 1 || quantity > 50);
srand(time(NULL));
int price = (rand() % 900000) + 10000;
printf("Price : Rp. %d\n",price);
pushMid(productName,quantity,price);
printf("Item successfuly added to cart !\n\n");
printf("Press any key to continue...\n");getchar();
}
void remove(){
int i = 0;
int index = 0;
if (i = view(0)){
do{
printf("Input the index : [1 - %d] : ",i);
scanf("%d",&index);getchar();
}while(index < 1 || index > i);
struct Cart* curr = head;
int count = 1;
while(curr){
if (count == index){
printf("\nThe product '%s' is deleted from cart !\n\n",curr->productName);
psopMid(curr->productName);
break;
}
count++;
curr = curr->next;
}
printf("Press any key to continue. . .\n");getchar();
}
}
void printEnter(){
for (int i = 0; i < 20;i++){
printf("\n");
}
}
void checkOut(){
int total = view(1);
printf("Total price : %d\n\n",total);
printEnter();
for(int i = 0; i < 3;i++){
printf(". ");
Sleep(1000);
}
printEnter();
printf("\n\nJust kidding ! \nTotal price : GRATIS !!! \n\nKindness if free\n");
getchar();
}
int main(){
int input = 0;
do{
do{
printEnter();
printf("My Market\n");
printf("===================\n");
printf("1. Add to Cart\n");
printf("2. View Cart\n");
printf("3. Remove Cart\n");
printf("4. Check Out\n");
printf(">> ");
scanf("%d",&input);getchar();
}while(input < 1 || input > 4);
switch(input){
case 1:{
printEnter();
buy();
break;
}
case 2:{
printEnter();
view(0);
break;
}
case 3:{
printEnter();
remove();
break;
}
case 4:{
printEnter();
checkOut();
break;
}
}
}while(input != 4);
return 0;
}
Comments
Post a Comment